Sử dụng phương pháp nhúng để tăng hiệu năng của hệ vi xử lý kiến trúc OpenRISC (Using Embedding methods to increase Efficience of MicroProcessor Systems with architecture OpenRISC)
Tác giả: ThS Phạm Văn Hiệp
Abstract: Ý tưởng tài nguyên mở nhằm cung cấp các thư viện và ứng dụng để hỗ trợ phát triển phần mềm, đã xuất hiện trong vài thập kỷ gần đây. Mục tiêu của bài báo này là đánh giá những ưu, nhược điểm của mô hình tài nguyên mở trong thiết kế hệ thống điện tử. Từ một kiến trúc mở, một hệ xử lý nền có thể tổng hợp được phát triển. Hệ xử lý nền gồm một CPU (OpenRISC) và một vài ngoại vi cơ bản như bus controller, watchdog and UART. Một tập các công cụ phát triển phần mềm (compiler, assembler, debugger) và RTOS (eCos) cũng được phát triển. Các bộ vi xử lý thông thường và các bộ xử lý tín hiệu số (DSP) có thể hỗ trợ các lệnh đa năng và một số thuật toán xử lý tín hiệu số nhất định như lọc số và biến đổi FFT. Tuy nhiên, chúng không hiệu quả với các yêu cầu khác của hệ thống thông tin như giải mã các mã điều khiển lỗi (Decoding error control codes) và các thuật toán có thể có trong tương lai. Bài báo này trình bày một bộ vi xử lý RISC đơn giản cho phép người dùng có thể thêm các lệnh tùy biến để tăng tốc các thuật toán phức tạp. Việc sử dụng đặc tính này được mô tả thông qua các ví dụ về giải mã Reed Solomon và thuật toán giải mã Turbo. Các ví dụ cho thấy có thể đạt được những cải thiện đáng kể về hiệu năng hệ thống bằng cách đưa thêm các lệnh tùy biến. Đặc tính này nên được sử dụng trong các hệ thống nhúng đòi hỏi các thuật toán phải được thực hiện một cách hiệu quả.
1. Kiến trúc OPENRISC
Các nghiên cứu gần đây đang tập trung thực hiện thiết kế RISC CPU dạng kiến trúc mở (gọi là OpenRISC 1200 hay OR1200). OR1200 là một RISC vô hương 32-bit với vi kiến trúc Havard, pipeline số nguyên 5 tầng hỗ trợ quản lý bộ nhớ ảo và các thao tác xử lý DSP cơ bản [3] chạy ở tần số 33 Mhz trên Virtex FPGA]. Mục đích của nó là tạo ra một kiến trúc OpenRISC chung cho phép các nhà thiết kế có thể ứng dụng kỹ thuật nhúng giúp giảm thời gian thiết kế hệ thống. Hình 1 mô tả kiến trúc OpenRISC này.
Kênh truyền thông cơ bản của kiến trúc này là một kênh Havard OpenCores. Nó gồm các kênh dữ liệu và kênh địa chỉ đồng bộ với nhiều kiến trúc Master/Slave. Một bộ phân chia kênh sẽ quyết định thiết bị nào được làm chủ kênh tại thời điểm hiện hành. Khối điều khiển kênh có nhiệm vụ là điều khiển các tham chiếu và nó được kết nối tới khối số nguyên qua các Cache lệnh và Cache dữ liệu. Khối điều khiển này cũng kết nối tới giao diện phát triển để thao tác với các ngoại vi. Kiến trúc này có các bộ nhớ ROM (kiểu Flash) và RAM. KhốiUART thực hiện truyền thông với giao thức RS232. Các nhà thiết kế OpenRISC đã chọn bộ UART 16550 (đây là một chuẩn công nghiệp thông dụng nhất) cho phép truy nhập bộ vi xử lý và RTOS từ bên ngoài. Điều này là quan trọng cho việc gỡ rối và nạp các phiên bản phần mềm mới cho OpenRISC. Bản đồ bộ nhớ của kiến trúc này có các vùng tạo cache và vùng bộ nhớ thông thường và nó có thể được đặt cấu hình bằng công cụ ECos RTOS.
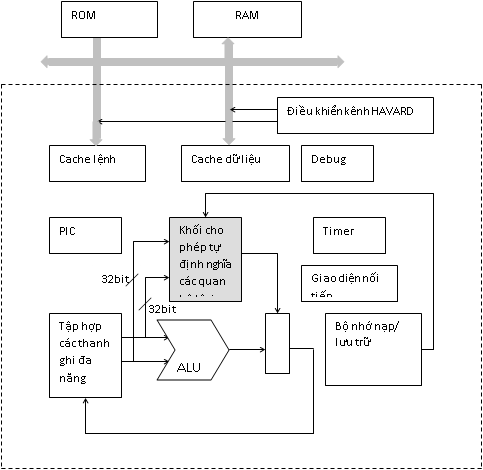
Hình 1. Kiến trúc OpenCore
CPU bao gồm khối thứ nhất là khối ALU có kiến trúc Pipeline cho phép tận dụng tần số clock cao hơn so với kiến trúc chung do vì tuyến dữ liệu được chia thành các tầng. Khối thứ hai là cache lệnh và cache dữ liệu (kiến trúc Havard) và mức độ kết hợp [3] được quyết định bằng việc đặt trọng số hợp lý nhằm dung hòa giữa thao tác thành công và độ phức tạp cấu trúc. Khối thứ ba là khối giám sát ngoại lệ để tính địa chỉ đặt thủ tục xử lý tình huống ngoại lệ và ra quyết định những thông tin nào về trạng thái của core phải được lưu giữ phục vụ cho việc khôi phục thực thi lệnh sau đó. Khối thứ tư là khối khối Debug và giao diện phát triển. Debug là một chức năng tùy chọn, nó cung cấp khả năng tạo ra các điểm dừng chương trình trên cơ sở so sánh với các giá trị được lưu và nạp, các địa chỉ bộ nhớ lệnh và dữ liệu. Thông qua giao diện phát triển, phần mềm Debug có thể phân tích trạng thái của CPU. Khối thứ tư là khối điều khiển ngắt PIC. Kiến trúc OpenRISC 1000 cung cấp 3 ngắt. Khối thứ năm là khối Tick timer với nhiệm vụ cung cấp cho phần mềm một clock chuẩn chính xác cho hệ thống. Khối thứ sáu là khối xác định hiệu năng trên nguyên tắc đếm số lần một sự kiện nhất định nào đó xảy ra như nhận lệnh, truy nhập nạp và lưu, các thao tác không thành công của cache ... Người lập trình có thể thu được thông tin số liệu về phần mềm được thực thi trên CPU bằng cách kiểm tra các bộ đếm này. Khối thứ bảy là khối giám sát nguồn cho phép giảm lượng tiêu thụ nguồn của Core. Khối này có thể thay đổi tần số clock, tắt các module hay buộc CPU vào chế độ nghỉ (sleep mode). Khối thứ tám là khối Watchdog dùng để cung cấp giải pháp cho các tình trạng lỗi phần mềm như chương trình bị quẩn trong vòng lặp vô hạn hoặc một thủ tục không hợp thức mà hệ thống không thể khôi phục được. Phần mềm này phải ghi vào một thanh ghi watchdog trước khi nó đạt tới một giá trị nhất định. Trong trường hợp ngược lại, watchdog sẽ gây ra một ngoại lệ reset, và trạng thái của CPU được đặt ngay lập tức về giá trị khởi tạo.
Khối cho phép tự định nghĩa các quan hệ lôgic bởi người dùng có thể là các hàm loogic từ đơn giản đến phức tạp. Việc bổ xung thêm phần cứng đươc thực hiện bằng phương pháp tái kiến trúc trên công nghệ FPGA. Giao diện ngoại vi tới lõi bộ vi xử lý không có gì thay đổi. Điều này giúp cho việc phát triển các hệ thống lớn ở đó việc thay đổi giao diện ngoại vi của môt khối sẽ yêu cầu sự kiểm tra nghiêm ngặt ở mức cao.
Việc hỗ trợ lập trình mức cao được cung cấp thông qua một bộ biên dịch C. Bộ vi xử lý được thiết kế theo hướng đơn giản, nhưng hỗ trợ việc thực thi hợp lý trong ngôn ngữ C. Mã assembly đã được tạo ra sẽ được hợp dịch và có thể được mô phỏng với một bộ mô phỏng bộ vi xử lý đơn giản. Mã đối tượng dùng để mô phỏng mã Verilog cho bộ vi xử lý nhằm thực hiện đồng thời mô phỏng phần cứng/phần mềm. Đặc trưng tài nguyên mở của hệ thống cho phép người sử dụng có thể thay đổi cả mô tả Verilog của bộ vi xử lý và thay đổi mã mô phỏng bộ vi xử lý khi cần bổ sung thêm phần cứng/ phần mềm. Điều này là quan trọng khi phát triển và thẩm định hiệu năng của các lệnh mới. Bộ vi xử lý được thiết kế theo hướng có thể tổng hợp và hoạt động với nhịp clock đơn.
Để kiểm tra hoạt động của phương án thiết kế có thể sử dụng các phương pháp sau:
<1>)Kiểm tra toàn bộ 100% số dòng lệnh.
<2>Kiểm tra ngẫu nhiên một số dòng lệnh.
<3>Một tập hợp các chương trình kiểm tra chức năng assembler.
Các bước sau được thực hiện nhằm kiểm tra phương án thiết kế với phép thử ngẫu nhiên:
<1>Kiểm tra Cache lệnh.
<2>Kiểm tra Cache dữ liệu.
<3>Kiểm tra toàn bộ Core (gồm tất cả các khối tùy chọn).
2. Bổ sung tập hợp lệnh cho các ứng dụng
<1>Với kiến trúc OpenRISC như trình bầy ở trên, việc bổ sung các lệnh định nghĩa bởi người dùng trong quá trình phát triển thiết kế có thể thực hiện như sau:
<2>Xác định các điểm thắt cổ chai khi thực thi mã lệnh và xác định các đoạn mã lệnh phù hợp cho việc tăng tốc [1,2].
<3>Sử dụng phương pháp mô phỏng để xem xét hiệu quả sự tăng tốc.
<4>Khi đạt được sự dung hòa giữa phần cứng và phần mềm, một mô tả lệnh tăng tốc được bổ sung vào khối cho phép tự định nghĩa các quan hệ lôgic bởi người dùng [4].
Các thay đổi chỉ thực hiện bên trong core bộ vi xử lý và do đó giao diện tới các phần khác của hệ thống nhúng có thể giữ nguyên, vì vậy thiết kế sẽ đạt tiêu chí tối giản phần cứng của hệ thống. Việc sử dụng các lệnh tăng tốc đã có thể đạt được bằng việc sử dụng các câu lệnh Assembly trong mã lệnh ngôn ngữ bậc cao.
Bổ sung các lệnh cho ứng dụng giải mã Turbo. Để giải mã Turbo đạt tốc độ cao, phép cộng trong miền log cần bổ sung được hàm tăng tốc để thực hiện chức năng giải mã. Hàm này có thể được mô tả như sau:
int INTlgsumexp (int a, int b)
{
int res;
asm (“udefinsn 10 %0 %1 %2”
: “=r” (res) : “r” (a), “r” (b) );
return res:
}
Trong đó udefinsn 10 rx ra rb tạo mối quan hệ giữa trường thanh ghi đa năng với phần cứng định nghĩa bới người dùng và giải mã lệnh số 10 và lưu kết quả vào thanh ghi rx. Khi mã lệnh gọi hàm như:
….
sum0=gam0_0+beta[k+1][0];
sum1=gam1_1+beta [k+1][1];
beta[k+1][0]=INTlgsumexp(sum0,sum1)
-maxv[k+1];
…..
Trong đó lệnh tăng tốc được nhúng và tối ưu hóa trong mã lệnh. Do đó, có thể đạt được hiệu năng cao cho các lệnh tăng tốc mà không cần mã hóa assembly bậc thấp.
Bổ sung các lệnh cho ứng dụng giải mã Reed Solomon
Xét trường hợp giải mã Reed Solomon (RS) như là một ứng dụng nguyên lý tài nguyên mở. Đó là một bộ mã RS trên trường GF(256) với 204 kí hiệu mã, 188 kí hiệu dữ liệu và có khả năng sửa lỗi 8 kí hiệu. Mã này được sử dụng trong ứng dụng truyền hình số DVB. Quá trình giải mã gồm 3 thao tác. Đầu tiên, 16 mẫu lỗi (syndromes) được tính toán trên cơ sở 204 kí hiệu 8 bit thu được. Nếu đó là dạng non zero thì có lỗi, ngược lại thì từ mã được coi là thu đúng. Nếu có lỗi, thuật toán Berlekamp-Massey được thực thi để tính toán hàm vị trí lỗi. Thuật toán này được sử dụng để xác định vị trí lỗi bằng một phép tìm kiếm Chien và các giá trị lỗi thực sự được tính toán sử dụng thuật toán Forney. Tất cả các thao tác này đều dựa trên việc sử dụng các tính toán trên các trường Galois được hỗ trợ bằng các bộ vi xử lý đa năng hay các DSP.
Bộ giải mã được viết bằng ngôn C sử dụng các bảng tham chiếu đối với các thao tác nhân và lấy nghịch đảo trên trường Galois. Mã lệnh được biên dịch với việc tối ưu hóa hoàn toàn. Mã kết quả yêu cầu 513332 chu kỳ clock để kiểm tra từ mã cho các lỗi và 821343 chu kỳ clock để kiểm tra và sửa 8 lỗi kí hiệu.
Với thao tác giải mã dựa chủ yếu vào việc sử dụng các thao tác trên trường Galois trên các kí hiệu 8 bit, việc sẵn có bộ vi xử lý tài nguyên mở có khả năng hỗ trợ thực hiện lệnh định nghĩa bởi người dùng tạo điều kiện đưa thêm các lệnh chuyên biệt để tăng tốc các thao tác mong muốn, như ở đây là các thao tác đại số Galois. Với kiến trúc bộ vi xử lý 32 bit, có thể thực hiện một thao tác vector của các thao tác trường Galois tại một thời điểm để tối đa hóa thông lượng của bộ vi xử lý. Do việc thực hiện chức năng trên mã ngôn ngữ C, một trong các thao tác đòi hỏi nhiều thời gian nhất là tính toán đa thức trên trường GF(256) và do đó việc tăng tốc thao tác này có thể đưa đến sự cải thiện mạnh mẽ về hiệu năng.
Để đáp ứng yêu cầu này, phần cứng tăng tốc được thực hiện để lưu 4 kí hiệu GF trong mỗi thanh ghi 32 bit R[30:0] theo nguyên tắc song song. Đây là một thanh ghi nội bộ cho phần cứng định nghĩa bởi người dùng. Một lệnh đơn chu kỳ đưa 2 đầu ra tệp thanh ghi A[31:0] và B[31:0] tới phần cứng tăng tốc. Phần cứng này tạo thành tổng:
S=S+(a0 x r0) + (a1 x r1) + (a2 x r2) + (a3 x r3)
Trong đó S là một thanh ghi 8 bit, a0=A[7:0], a1=A[15:8],…., r0=R[7:0], r1=R[15:8],…, và các phép tính thực hiện trên trường GF(256). Đồng thời thanh ghi nội bộ R được cập nhật là:
r0=(r0 x b0); r1=(r1 x b1); r2=(r2 x b2); r0=(r3 x b3);
Vì vậy, nếu thanh ghi R được khởi tạo bằng {x3,x2,x1,x0} thì việc lấy giá trị {a3,a2,a1,a0} từ các thanh ghi và cộng giá trị a3x3+a2x2+a1x1+a0x0 vào thanh ghi tổng rồi cập nhật thanh ghi R thành {x7,x6,x5,x4} cho phép đánh giá 4 thành phần trong ước lượng đa thức trên trường GF(256) và chuẩn bị cho 4 thành phần kế tiếp trong một chu kỳ clock.
Lệnh đơn này cho phép một đa thức N thành phần có thể được đánh giá trong N/4 chu kỳ nếu dữ liệu đã được lưu trong các thanh ghi. Các lệnh bổ sung được cung cấp để nạp thanh ghi R cũng như đọc và xóa thanh ghi tổng. Ngoài ra còn có một lệnh được cung cấp để thực hiện phép nhân vector của 4 phần tử GF(256).
Kết luận
Trong bài báo này, nhằm thực hiện kỹ thuật nhúng bổ xung nhanh cấu trúc lệnh chức năng vào CPU đã sử dụng kiến trúc gồm một CPU OpenRISC, một số thiết bị ngoại vi cơ bản và một Kit phát triển phần mềm. Cho CPU chạy mô phỏng với phần mềm 14000 dòng lệnh và các ngoại vi là 2500 dòng lệnh. Ưu điểm chính của kiến trúc OpenRISC là cho phép thiết kế một core có thể thẩm định các thông số kỹ thuật hệ thống và tương thích nó với các ứng dụng khác. Các ví dụ về giải mã Reed Solomon và thuật toán sử dụng trong giải mã Turbo được đưa ra để mô tả việc sử dụng phần cứng tăng tốc. Trong thực tế, có thể thực hiện rất đa dạng các kết hợp phần cứng/phần mềm cho phép đạt được sự dung hòa giữa độ phức tạp về phần cứng và hiệu năng hệ thống. Đặc tính tài nguyên mở của thiết kế và khả năng lập trình với ngôn ngữ bậc cao cho phép người thiết kế có thể đánh giá và phát triển các lệnh mới cho phép nâng cao đáng kể hiệu năng của những khâu trọng yếu trong thiết kế hệ thống nhúng. Điều này có thể được thực hiện trong bản thân lõi bộ vi xử lý nên vẫn giữ nguyên các giao diện và bổ sung thiết kế của hệ thống nhúng phức tạp.
Tài liệu tham khảo
1. Do Xuan Tien (1999), Parallel algorithms to design multiprocessor systems. Journal of science and technique. No 88 /III, pp 11-19.
2. Nguyễn Minh Ngọc, Đỗ Xuân Tiến (2007), “Tái kiến trúc Pipeline chức năng theo tiêu chuẩn độ trễ tối thiểu ML”, Tạp chí Khoa học kỹ thuật, Học viện KTQS, Số 120 / III trang 5-14, Hà Nội.
3. OpenRISC 1000 Architecture Manual. OpenCores, January 28th, 2003.
Iksoo Pyo, et al., “Application-Driven Design Automation for Microprocessor Design” Proc. 29th DAC, June, 1992.
4. Anthony J. Massa. Embedded Software Development with eCos. Prentice Hall, 2002.

- Trao quyết định nghiệm thu đề tài Nghiên cứu chế tạo quạt cây chạy bằng Ắc quy và điện lưới
- Một số giải pháp nâng cao hiệu quả hoạt động sáng kiến, cải tiến kỹ thuật trong việc tăng cường chất lượng thực hành cho sinh viên
- 10 sự kiện Khoa học và Công nghệ nổi bật trong năm 2015
- Đề tài: Xử lý bã cafe làm phân hữu cơ vi sinh
- Máy phát điện thủy khí ACBell
- Việt Nam phát triển điện mặt trời theo hình thức nào là phù hợp
- Đề tài: Máy bơm nước bằng điện mặt trời
- Nghiên cứu lựa chọn và ứng dụng các giải pháp hợp lý áp dụng cho lưới điện phân phối việt nam đạt tiêu chuẩn lưới thông minh, mã số: kc.05.12/11-15
- Nghiên cứu khảo sát Lập bản đồ đánh giá thổ nhưỡng, khí hậu của một số vùng cây đặc sản của địa phương từ đó xây dựng quy trình chăm sóc, bảo tồn và nhân rộng Một số đặc sản
- Đề tài: Xây dựng mô hình và triển khai dự án điện mặt trời nối lưới cho các đơn vị hành chính hoặc các trường học tại các địa bàn còn gặp nhiều khó khăn
- Một số vấn đề về cơ chế tài chính với hoạt động khoa học và công nghệ ở Việt Nam
- Đầu tư trực tiếp nước ngoài ( fdi) vào Việt Nam dưới góc độ quản lý kinh tế vĩ mô
- Công trình nghiên cứu khoa học của Trường Đại học Quốc tế Bắc Hà trong chương trình “7 ngày công nghệ”
- Đề tài: Nghiên cứu giải pháp tổng thể trong lĩnh vực nông nghiệp sinh thái công nghệ cao phù hợp với địa hình địa lý và thổ nhưỡng của địa phương
- Đề tài: Xây dựng và triển khai dự án điện mặt trời nối lưới công suất từ 3 đến 5 KW tại trung tâm làm mô hình điểm và đánh giá kết quả. Từ đó nhân rộng trên toàn tỉnh.
- Lưới điện thông minh tại trạm biến áp hạ áp
- Fast synthesis of PbS nanoparticles for fabrication of glucose sensor with enhanced sensitivity
- Ứng dụng pin mặt trời vào bơm nước và thắp sáng đèn Led cho cây trồng, vật nuôi
- Đề tài cấp Nhà nước
- Kết quả và Kết luận của khảo sát
- Đề tài nghiên cứu
- Đề tài: Mô hình tầu cao tốc có tốc độ ngang với máy bay
- Phương pháp đo nội trở để kiểm tra chất lượng ACCU - Measuring internal resistance to test battery
- Ứng dụng kỹ thuật điện tử công suất để điều khiển đóng cắt và thay đổi tham số các thiết bị bù trong lưới điện
- Việt nam phát triển điện mặt trời theo hình thức nào là phù hợp
- Quy trình chế tạo IC từ phiến silicon.
- Giải pháp hữu ích: gạch định hình
- Xây dựng bài toán bù tối ưu và phương pháp thiết kế bù công suất phản kháng, nâng cao hệ số Cos
- Nghiên cứu thủ tục truy nhập đa phương tiện cho hệ thông băng thông rộng đa truy nhập theo mã và thời gian với việc sử dụng thuật toán điều khiển công suất cực tiểu và xây dựng lịch trình xử lý
Tin cùng loại
